



- 商品详情
- 配送说明
- 兑换说明
2025年年初,DeepSeek 成为全球人工智能(AI)领域的焦点,其DeepSeek-V3 和DeepSeek-R1 版本在行业内引发了结构性震动。
DeepSeek-V3 是一个拥有 6710 亿个参数的混合专家模型(MoE) ,每个token(模型处理文本的基本单位)激活 370 亿个参数。该模型在 14.8 万亿个高质量 token上进行预训练,采用 MLA 和 MoE 架构。DeepSeek-V3 的发布几乎没有预热和炒作,仅凭借其出色的效果和超低的成本迅速走红。
DeepSeek-R1 则是在 DeepSeek-V3 的基础上构建的推理模型,它在后训练阶段大规模使用强化学习技术,仅凭极少标注数据便大幅提升了模型的推理能力。在数学、代码、自然语言推理等任务上,DeepSeek-R1 的效果已可比肩 OpenAI-o1 正式版。
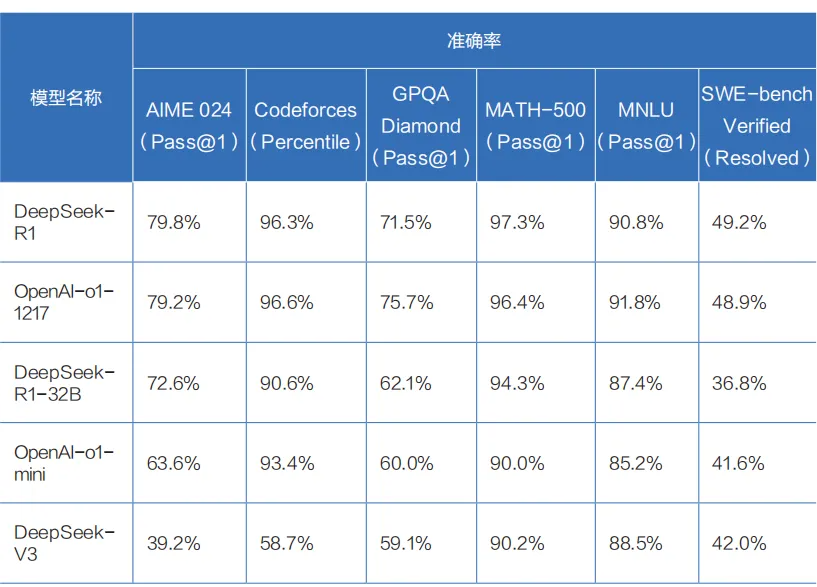
DeepSeek-R1 在基准测试中的表现
DeepSeek-V3技术突破
DeepSeek-V3 的模型架构整体上基于 Transformer 的 MoE 架构,并在细节实现上做了大量的创新和优化,如大量小专家模型、多头潜在注意力、无辅助损失的负载平衡、多token预测技术(MTP) 等,大幅提升了模型的性能。
在模型训练方面,DeepSeek 依托自研的轻量级分布式训练框架 HAI-LLM,通过算法、框架和硬件的紧密配合,突破了跨节点 MoE 训练中的通信瓶颈,实现了高效稳定的训练。DeepSeek-V3 是业界率先使用 FP8 进行混合精度训练的开源模型。
在推理部署方面,DeepSeek-V3 采用 预填充(Prefilling)和解码(Decoding)分离的策略 ,以及冗余专家策略,在提高推理速度的同时确保了系统的稳定性和可靠性。
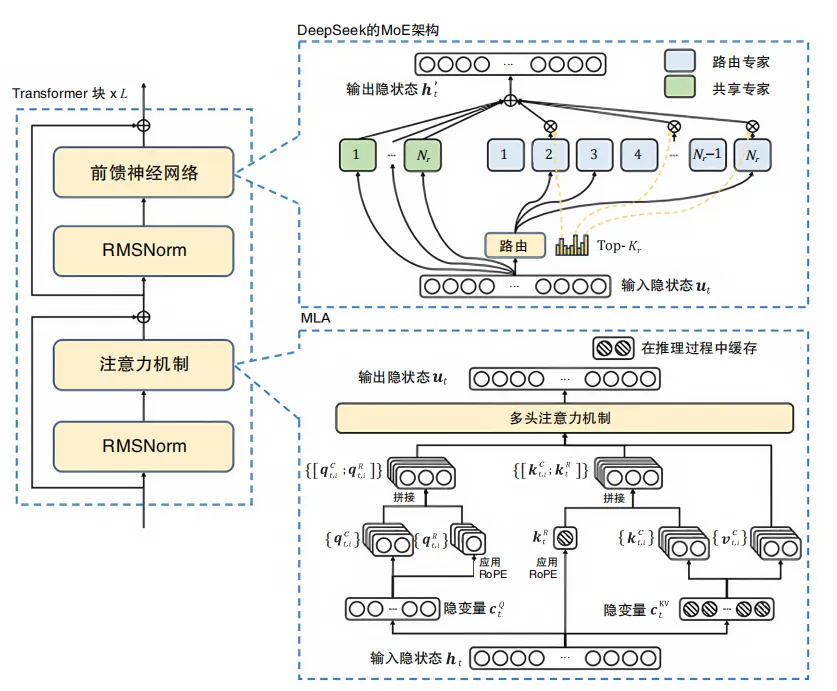
DeepSeek 架构图
